关于 Git 分支的模型有不少种,目前我读到的、以及实践中获取的最佳模型,是下面这篇文章所讲:
下面,我以自己的理解,对文章里的重点做一些提取。
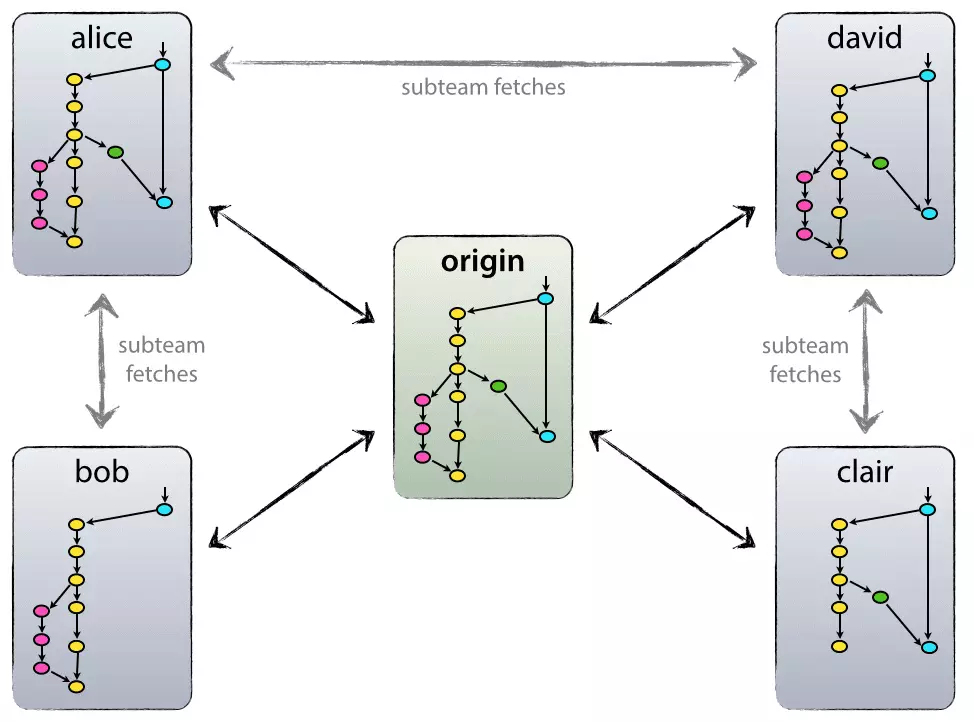
分布式
如下图
- origin 并不是中心,只表示原始仓库,git 是分布式的(无中心)
- 可以从任意结点同步,包括 origin 和其它开发者
分支类型
代码分支
| 分支 | 共享 | 生命期 | 来源 | 合并到 | 命名 |
|---|---|---|---|---|---|
| 主分支(master) | ✓ | 永久 | - | - | - |
| 开发分支(develop) | ✓ | 永久 | - | - | - |
| 功能分支(feature) | ✗ | 合并后删除 | develop | develop | feature-* |
| 发行分支(release) | ✗ | 合并后删除 | develop | develop master |
release-<版本号> |
| 热补丁分支(hotfix) | ✗ | 合并后删除 | release | develop master |
hotfix-<新版本号> |
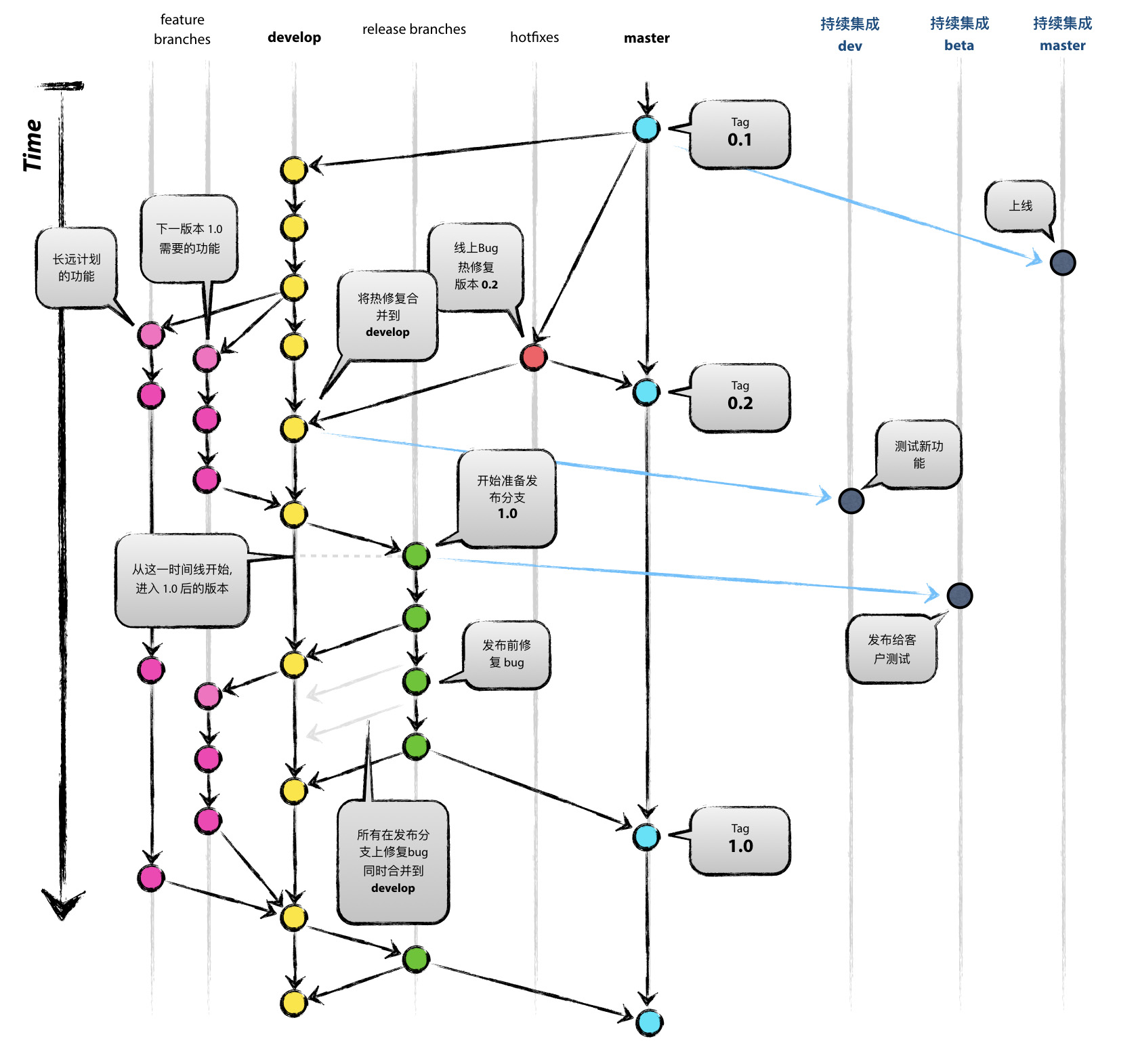
master 分支
- HEAD 永远指向最新的发布点
develop 分支
- HEAD 永远指向最新的功能需求,nightly building 的来源
release 分支
- 不允许添加新功能
hotfix 分支
- 为了并行开发,修复 bug 同时,不影响 develop 分支开发新功能
- 当有一个 Release 分支存在时,Hotfix 分支应该合并到该 Release 分支,而不是 develop 分支
持续集成分支
由于使用了持续集成部署,它会监测某个分支的提交来触发完成新版本部署,所以我们定义了两个新分支和复用上面一个分支,专门用于持续集成。
| 分支 | 来源 | 代码 | 数据库 | 目的 |
|---|---|---|---|---|
| dev | feature hotfix develop |
覆盖 | 覆盖 | 内部开发测试 |
| beta | release | 覆盖 | 覆盖 | 客户协同测试 |
| master | master | 覆盖 | 覆盖 | 上线部署 |
分支协作图
实践与讨论
1. 持续集成的冲突
时间点1
- 开发甲:从 develop 分支创建 feature-A
- 开发乙:从 develop 分支创建 feature-B
时间点2
- 开发甲:初步完成 feature-A,合并到 dev 分支,触发自动部署到开发服务器并修改了数据库结构
时间点3
- 开发乙:初步完成 feature-B,待测试,需要合并到 dev 分支触发自动部署,但是与新数据结构不匹配
这时,乙该如何做?
- 方案1:保留 feature-A,合并 feature-B,但数据库不能兼容
- 方案2:覆盖甲提交的 feature-A,同时还原数据库,但是 feature-A 不能再继续测试了
2. 一个功能,提交多次 vs 提交一次?no-ff vs fast forward?
举例,后端开发功能:用户登录验证接口,需要提供传统用户名登录和短信验证码登录两类接口
按照开发过程,我们一般会经历:修改数据库 -> 用户名密码登录接口 -> 短信验证码登录接口 三个阶段
当开发完成时,我们是提交3次(修改数据库 -> 用户名密码登录接口 -> 短信验证码登录接口)还是合并成一次提交呢?
显然,3次提交更清晰,可维护性更好,当出现问题时,直接找到对应提交并处理,要比处理一个合并后的提交更高效、可靠。
当将这个功能合并到开发分支时,使用 no-ff 参数,可以保留提交的“批次”,也就是这个功能所包含了一批提交。这样做的好处是,当整个功能都需要回滚时,能更清晰分辨哪些提交要一起回滚。如下图所示:
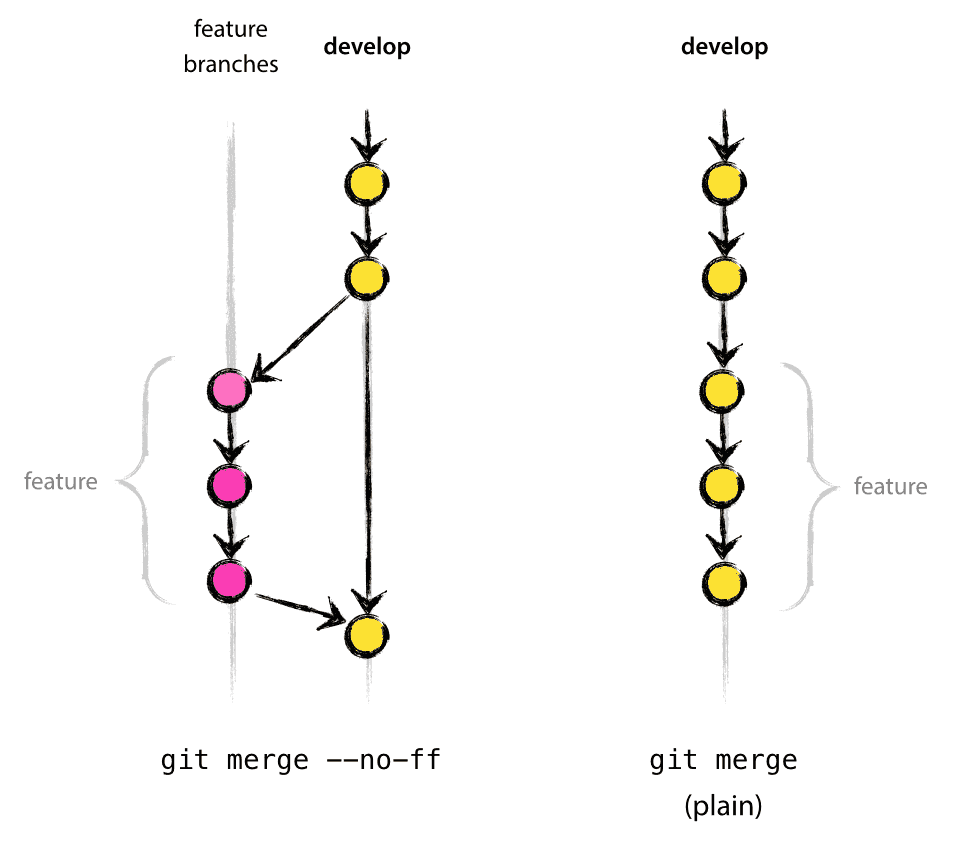
所以,这个问题的结论是:使用多次提交,当合并的功能包含多次提交时,加上 no-ff 参数。